Highlights from the 1st Workshop on Multilingual Representation Learning at EMNLP 2021
Last few years have seen significant advances in natural language processing (NLP) of under-studied languages, mainly due to the development of new methods demonstrating potential for successful adaptation of models from high-resourced settings into languages with little to no training resources. Generally referred to as multilingual representation learning, these methods are found to be extremely efficient in learning features useful for transfer learning between languages.
Despite the increasing availability of new approaches, recent findings still suggest the methods could be further improved in transferring to languages with for instance distant grammatical characteristics, different tokenization or ortographic properties with the high-resource language model, especially under zero to few-shot settings. One of the main reasons that limit developing better models that can also address such issues is the lack of public benchmarks that include more languages. Most popular NLP tasks typically only have evaluation data in English, which keeps the evaluation of many NLP tasks very restricted in terms of linguistic typology. Such evaluation results, in particular when negative, often tend to fail to find a venue where they could be shared for further progress.
With the increasing interest in the topic and number of research contributions exploring different methods for multilingual representation learning, a shared venue and community has become essential to be able to discuss latest findings, enhance and share our understanding of applicability in different languages or settings where the methods could be useful. Aiming to address all of these issues, this year was the first in the organization of the Workshop on Multilingual Representation Learning (MRL), which aimed to foster the nascent community composed of research groups working on machine learning, linguistic typology, and real-life applications of NLP tasks in various languages, and to ultimately accelerate the progress in the field with new techniques and evaluation methods.
The workshop attracted a large interest with 50+ submissions out of which 19 long papers and 5 extended abstracts were accepted. Here we present some findings and statistics of the 1st Workshop on Multilingual Representation Learning 2021. Interested readers can find the submission statistics for more details on the characteristics of submissions as well as findings from the featured studies sorted according to the topics of interest and the type of proposed methodology.
Table of Contents
- Submission statistics
- Multilingual pre-trained models
- Crosslingual word embeddings
- Crosslingual transfer learning
- Generative models
- Benchmarks and Data sets
- Final remarks
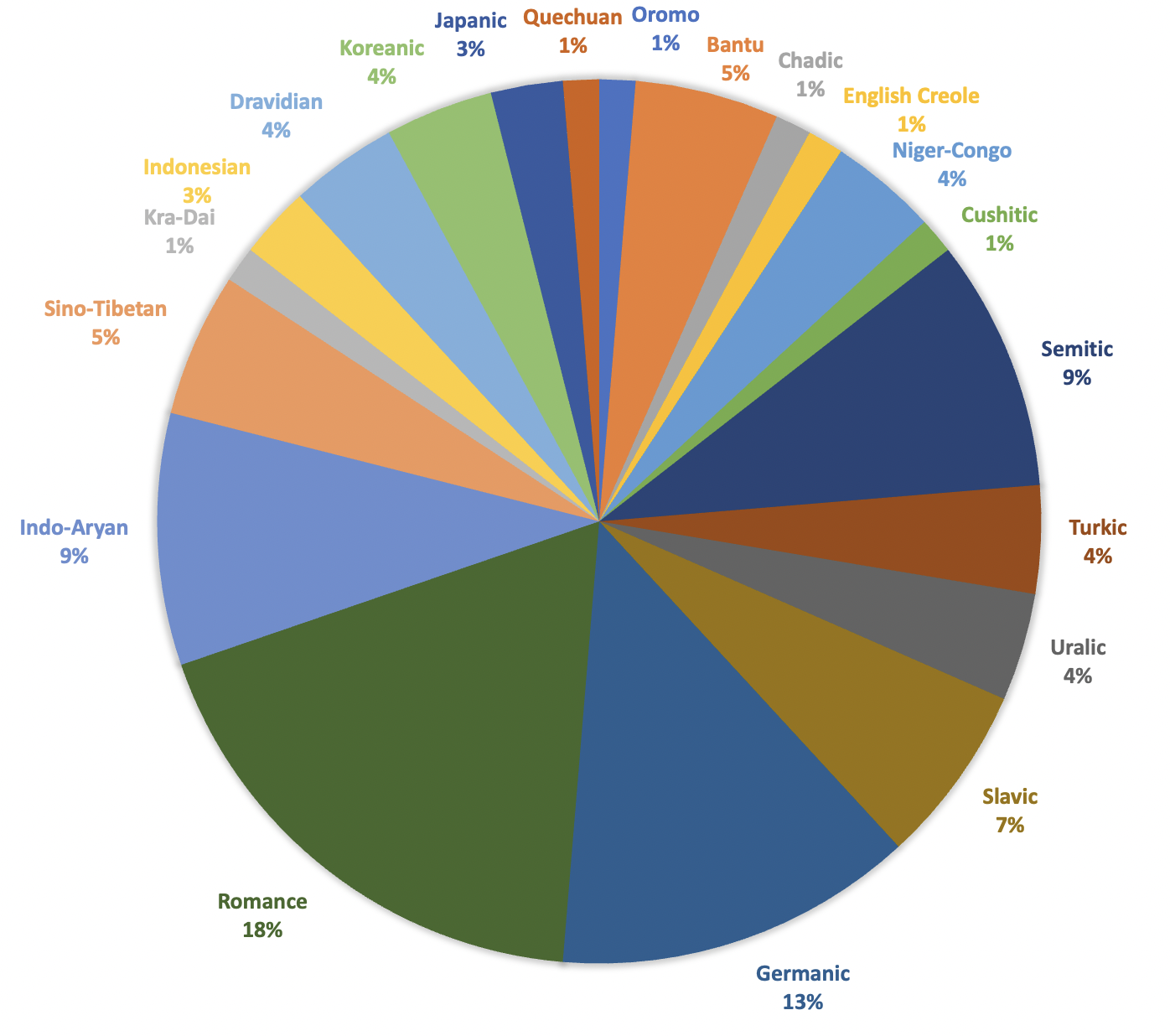
With a wide array of topics of interest, the workshop appeals to all types of research involving multi-lingual representation learning methods. In order to promote new directions in research, the workshop maintains a very general standing point, allowing the research presented to vary in terms of settings and applications. This year the submissions included 18 different types of studies, ranging from novel cross-lingual transfer methods or their evaluation in different NLP tasks, different approaches to probing tasks, new benchmarks, and focused analysis of crosslingual embeddings or language models commonly used in NLP systems.
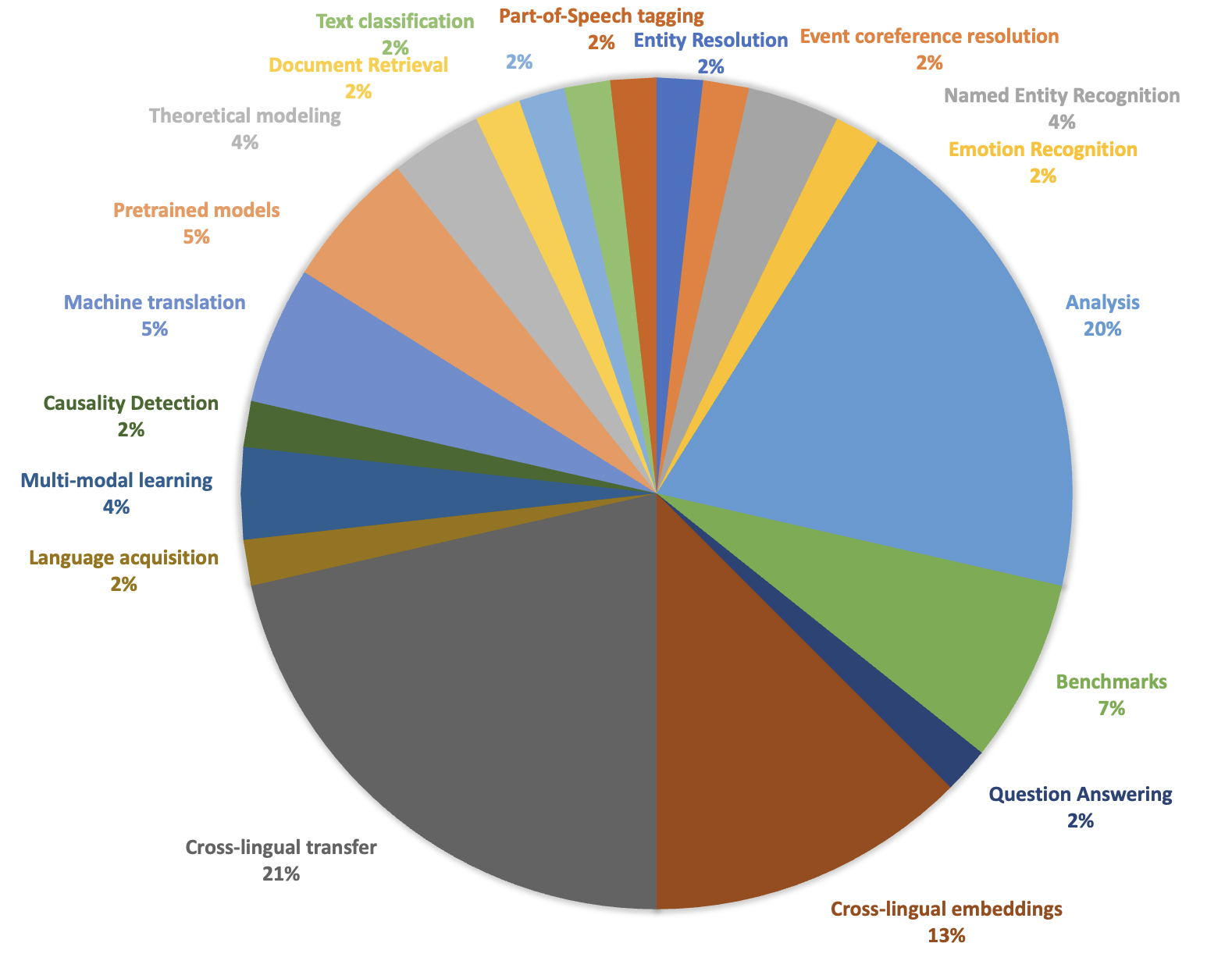
The submissions were also very diverse in terms of the studied languages, with papers reporting results from at least 20 different language families, many of which reported first results on under-studied languages across various NLP tasks. The languages studied the most were Romance languages, including Italian, French and Spanish, followed by Germanic languages, most of which were papers with results in English NLP, and one paper with results in German. The rest of the papers were mostly balanced in terms of the languages used in evaluation, with papers usually reporting results in at least 2 to 3 typologically diverse language families.
With a diverse set of results presenting novel findings on how various methods used in prominent NLP systems perform in previously understudied tasks and languages, as well as new perspectives to consider at the design of multilingual representation learning methods, we present a summary of the collection of papers presented in the workshop.
Multilingual pre-trained models
The workshop program included a diverse set of high quality papers studying various aspects of multilingual representation learning methods. The majority of the papers generally focused on analyzing multilingual language models or crosslingual embedding learning methods to understand how cross-lingual transfer takes place and to present interesting findings that help enhance our understanding of different factors affecting the transfer performance.
An interesting study by Winata et al. evaluate crosslingual transfer especially under few-shot and zero-shot settings using large pre-trained models, including the GPT and T5 models. Their experiments include languages from the Latin language family, with the same phonetic script as well as grammatical structure, and they observe competitive results.

On the other hand, Chau and Smith’s empirical study ‘Specializing Multilingual Models’ is an instance where characteristics of the input representations are analyzed to assess what is the optimal input representation to increase the quality of transfer across languages. The experiments particularly focus on capturing the limiting effects of differences in input language scripts and tokenization models in multilingual BERT and are evaluated in 9 languages from 8 typologically diverse language families in named entity recognition, part-of-speech tagging and dependency parsing. Especially for languages with different scripts, they find strong limitations of different scripts and tokenization methods for transfer across typologically different languages.

On the bright side, there are recent methods that propose novel methods for pre-training multilingual language models where the performance of cross-lingual transfer do not necessarily deteriorate in the low-resource languages in the training corpus. Ogueji et al. with their AfriBERTa model, show that using a balanced training set one can build reliable language models in low-resource languages.
A relatively earlier approach to multilingual representation learning methods, explicit learning of cross-lingual alignment based contextual models still prove useful in many NLP tasks such as bilingual lexicon induction or machine translation. On the other hand, such methods may fall back in producing good quality representations when sufficient amount of training data, either monolingual data or, in the supervised case, also parallel data are not available. In their case study on low-resource Occitan cross-lingual word embeddings, Woller et al. propose leveraging data from related languages like Spanish and French and achieve very useful progress in the performance.
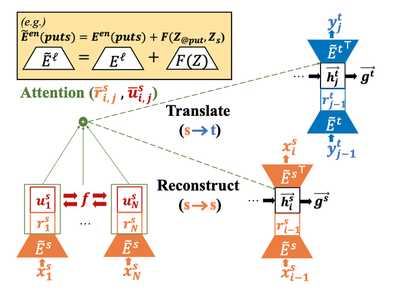
Wada et al.’s paper, on the other hand, suggests using parallel data with shared embeddings and finds this method useful in particular for extremely low-resource languages where even a moderate amount of monolingual data is not available.
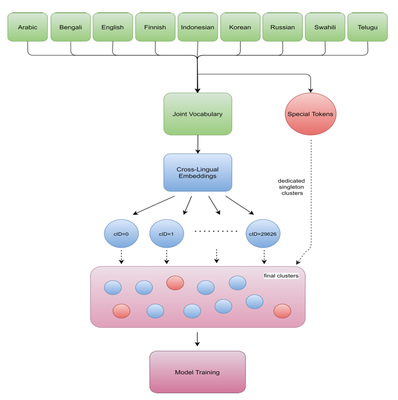
Besides data augmentation methods, an interesting proposal by Bassani et al. is to instead use monolingual vocabularies for cross-lingual generalization. Their proposed multilingual vocabulary induction method learned a shared vocabulary by clustering subwords that are semantically related, therefore avoiding cross-lingual contextual ambiguities. Their multilingual models provide improvements in the TyDiQA-GoldP benchmark for question answering covering nine languages.
Cserháti and Berend examine another potential reason to fall-back on cross-lingual alignment models: content overlap in training data, specifically the domain of collected resources used in building the unsupervised alignment model. They find corpus size and distributional similarity are important factors that affect the overall performance. They suggest that large scale and widely diverse data sets like the English Wikipedia may often be inappropriate for training cross-lingual embeddings compared to the data sets in other languages which are usually smaller and are more concentrated in terms of topics.
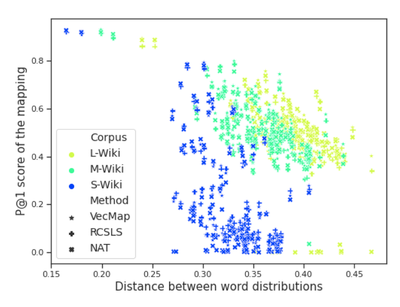
In conclusion, while providing a promising approach to achieve universal contextual representations, cross-lingual embeddings can still suffer greatly from imbalance and sparsity in data distributions. Further progress on this problem may focus on enhanced approaches to data augmentation as well as changes in the learning model.
Crosslingual transfer learning
Despite the development of many learning algorithms and architectures for cross-lingual representations, the coherence of these representations with the actual semantic space of languages is still not clearly well understood.
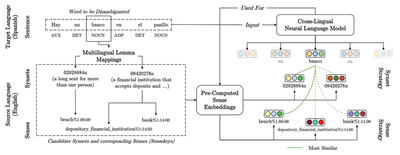
Rezaee et al.’s study on the cross-lingual transferability of contextualized sense embeddings aims to demonstrate to what extent semantic information aligns in practice across languages. Their analysis in the cross-lingual word sense disambiguation task suggests using large pre-trained language models and a treebank for cross-lingual annotation (e.g. BabelNet) for one can adapt annotated sense knowledge into new languages. The results, however, are restricted to within the same language family (Romance languages in their experiments).
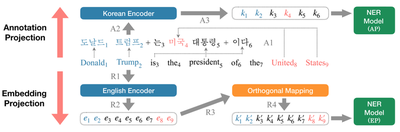
In distant language pairs, however, the conventional transfer approaches may still perform poorly. In their paper on zero-shot learning between English and Korean for named entity recognition, Kim et al. compare different zero-shot adaptation methods, including Wu and Dredze (2019)’s direct model transfer, and the embedding projection or annotation projection methods of Ni et al. (2017). They find the annotation projection method, which aligns words across two languages and pseudo-annotates Korean sentences to be used for training the annotation model, produces a fair quality of noisy annotations and achieves the best overall transfer performance.
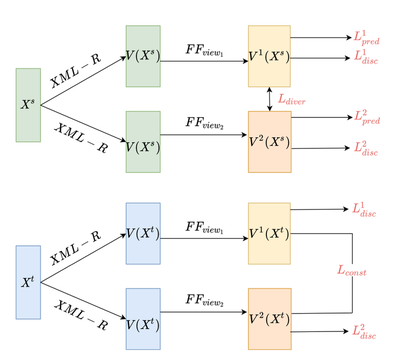
Achieving successful cross-lingual transfer in more challenging prediction tasks, on the other hand, might still fail especially considering general cases of transfer across languages possibly with different typology. For instance, in the event coresolution task, there is no publicly available annotated data for languages other than English. Phung et al. in their study on learning cross-lingual representations for event coreference resolution with multi-view alignment and optimal transport. Also proposing the first baseline system in this task, the authors implement language adversarial neural networks to define a multi-lingual alignment objective which obtains significant improvements over the conventional downstream transfer approach based on multilingual pre-trained models, and suggest to work even across distant languages (e.g. English-Spanish and English-Chinese). Gupta also deploys adversarial training in the multi-lingual emotion recognition task and obtains promising results even in the semi-supervised settings where a mixture of annotated and unannotated data are used in training. Due to these successful demonstrations, adversarial training seems to remain a promising direction in cross-lingual transfer learning.
Another highly relevant multilingual prediction task especially for related languages and dialects and observed commonly on online data is code switching. Prasad et al. approach the problem as a multi-task problem where they define intermediate and end tasks as the code-switched (mixture of Hindi/English) and monolingual prediction tasks (Hindi and English benchmarks), respectively. The intermediate task training approach is implemented as gradual fine-tuning of the large multi-lingual pre-trained language model on the intermediate and end tasks. The approach is simple to implement and can be useful to handle noise in the data of this type.
Krishnan et al., on the other hand, present an alternative approach where they explicitly use the code-switched data in order to improve cross-lingual transfer and find surprising results where the method allows improvements on languages that are not even closely related.
Although cross-lingual transfer has become a widely studied topic, its extensions to generative models remain mostly unexplored. Evaluation in generative tasks also allows more extensive assessment of detailed characteristics on the model’s capacity and performance in learning different types of abstract features.
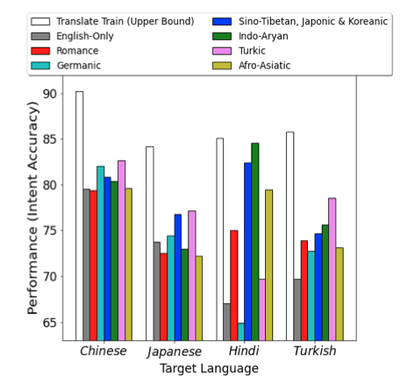
K et al.’s study on analyzing the effects of reasoning types on cross-lingual transfer performance extends the TaxiNLI (Joshi, 2020) benchmark to the multi-lingual setting so that the capacity of language models in solving different inference tasks could be compared across languages as well as how much knowledge is required to solve different types of tasks are transferrable to different languages. They observe that the transferability of different inference types is non-uniform, especially in the case of XLM-R. In particular, transferability of negation generally seems easier than lexical, syntactic, boolean, or knowledge inference types. In the exceptional case of Swahili, the agglutinative morphology may make it difficult to infer negation information which is encoded as a prefix.
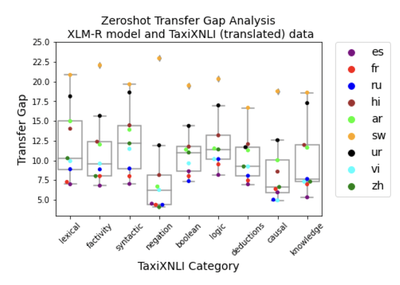
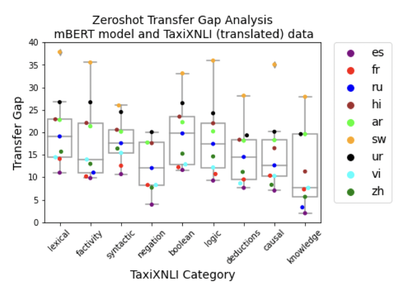
They also find the results uniformly improve in the few-shot learning case where cross-lingual alignments may be improved, although some categories, especially the causality inference task remain equally difficult for the models to solve despite addition of data. The study shows how current models still fail in generalizing even the simplest abstraction tasks and how different instances of representation such as morphological structure, possibly due to tokenization, may be restricting learning important features for generalization.
Another quite challenging task in NLP, even with the existence of data, is paraphrasing, and Jegadeesan et al. decide to solve it for the zero-shot case. In their study on improving the diversity of unsupervised paraphrasing with embedding outputs, they build an end-to-end multi-lingual paraphrasing model which is trained using jointly the translation and the auto-encoding objectives and find that their model is able to outperform even the monolingual paraphrasing models.
Multi-task and multi-lingual learning are both very promising directions and we hope to be seeing these methods successfully deployed in other tasks to improve the performance for unsupervised and zero-shot cases.
The workshop program also included many new evaluation benchmarks and data sets enhancing the diversity of benchmarks for multi-lingual models into new language families.
An important aspect still not completely resolved in multi-lingual processing is the learning and generalization of syntactic structure. Taktasheva et al. propose a new benchmark prepared by different perturbation techniques specifically for performing syntactic probing in multi-lingual language models in three Indo-European languages with varying syntactic typology, which includes English, Swedish and Russian. Their evaluation of multi-lingual models using the data sets reveals the significant role of the training objective in determining the sensitivity of the pre-trained models on the input word order. Another crucial finding suggests the models do not seem to rely on positional encodings as might have been expected in learning and constructing syntactic structure. Another benchmark for syntactic evaluation is Vyākarana by Patil et al. who curate new data sets in Indic languages in four syntax-related tasks: PoS Tagging, Syntax Tree-depth Prediction, Grammatical Case Marking, and Subject- Verb Agreement. Their benchmark reveals the limited capacity of popular multi-lingual models such as XLM-R and mBERT in performing competitively in many tasks requiring syntactic knowledge, although they do find significant advantages of using the multi-lingual variants over the monolingual models like the IndicBERT.
Some of the original contributions at the program also included novel tasks for involving multi-lingual modeling, including Mr. TYDI: A Multi-lingual Benchmark for Dense Retrieval by Zhang et al. designed to evaluate dense retrieval in eleven typologically diverse languages, and VisualSem: A High-quality Knowledge Graph for Vision & Language by Alberts et al., a high-quality knowledge graph (KG) which includes nodes with multilingual glosses of illustrative images depicting relevance and relationships in 14 different languages.

Providing a new means for communicating and discussing ideas on how to understand and improve multi-lingual representation learning methods, the workshop in summary had many original contributions that enhanced our perspective on how different approaches work in extended evaluation settings and potential ways to improve them. Fine-tuning pre-trained language models for few to zero-shot transfer learning remains a popular as well as a rather competitive baseline, whereas the findings collected from various papers suggest in particular that changes in the writing system and tokenization from the source to the target language are a substantial obstacle for gaining good performance with cross-lingual transfer. Extensions to the fine-tuning objective using methods like adversarial or multi-task learning are promising directions, although further research would certainly be necessary until a successful and efficient fine-tuning strategy can be developed. The workshop also allowed publishing many new evaluation benchmarks, which made it possible to see the performance of different multi-lingual NLP systems in previously under-assessed or evaluated languages. Such results are essential to really assess how representative and competitive are our models and hopefully will keep attracting more research in the coming years.
More details of the workshop program, including invited talks by world experts on the field, including Graham Neubig, Yulia Tsvetkov and Melvin Johnson, are available on the website. The second edition of the worshop is already confirmed to take place with EMNLP 2022 and more updates will be announced soon.
Special thanks to Sebastian Ruder for editing the post and to all participants that allowed creating a new research community that made gathering and sharing these findings possible.
References
- Joshi, P., Aditya, S., Sathe, A., & Choudhury, M. (2020). TaxiNLI: Taking a Ride up the NLU Hill. In Proceedings of the 24th Conference on Computational Natural Language Learning (pp. 41-55).
- Ni, J., Dinu, G., & Florian, R. (2017). Weakly Supervised Cross-Lingual Named Entity Recognition via Effective Annotation and Representation Projection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1470-1480).
- Wu, S., & Dredze, M. (2019). Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 833-844).